

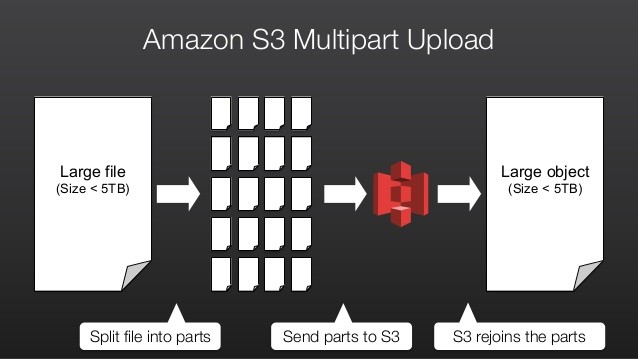
Mở đầu
Hầu hết các dịch vụ lưu trữ dữ liệu dạng đám mây (online storage) hiện nay như: Google One, One Drive, Dropbox, Mega,… đều sử dụng kỹ thuật băm nhỏ các object (file, thư mục) lớn thành nhiều mảnh có kích thước nhỏ trước khi upload lên hệ thống (hay nói ngắn gọn multipart là anh IT đều hiểu). Dĩ nhiên, một dịch vụ lưu trữ object top đầu như AWS S3 cũng không ngoại lệ.
Trước khi đi vào bài lab multipart trên AWS S3, mình xin tóm tắt nhẹ một số ưu điểm của kỹ thuật này nhé:
- Các part của một file có thể được upload đồng thời và không tuân thủ bất kỳ thứ tự nào, từ đó giúp tối ưu hóa băng thông internet anh em đang có.
- Chỉ thực hiện upload lại bất kỳ part nào bị lỗi, từ đó tiết kiệm tổng thời gian tải file nếu chẳng may có sự cố đường truyền trong lúc upload.
- Tạm dừng hoặc tiếp tục upload: Có thể upload các part của object bất cứ lúc nào. Nhưng phải đảm bảo hoàn thành hoặc dừng multipart upload vì các part đã upload vẫn còn lưu trữ trên S3.
- Thực hiện upload trước khi một file lớn được tạo hoàn tất.
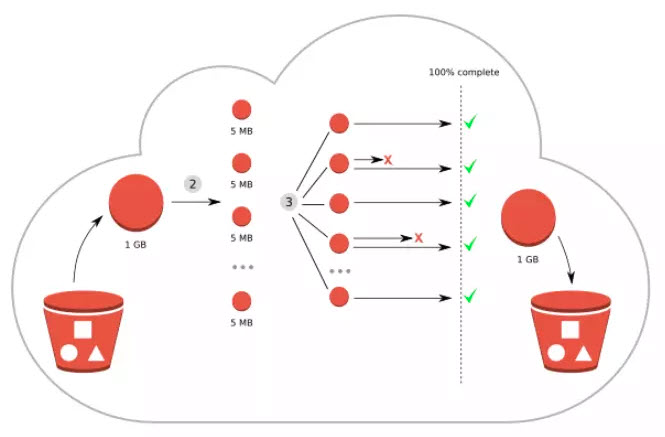
Lab steps
Task 1: Tạo S3 bucket
1. Ở phần đầu tiên này anh em sẽ phải tạo Bucket ở hai region khác nhau (phải enable versioning trên cả 2 bucket). Ví dụ trong nội dung bài viết này mình sẽ tạo bucket: b-hiepsharing-saa
Do cũng đã chia sẻ nhiều bài viết về S3 rồi nên mình sẽ bỏ qua chi tiết các bước để khởi tạo
2. Sau khi khởi tạo thành công, anh em quay lại giao diện Amazon S3 > Buckets sẽ thấy bucket tương tự minh họa bên dưới:

Task 2: Chuẩn bị công cụ và môi trường tương tác
Sẽ có nhiều cách để anh em thực hiện bài multipart upload này như: dùng API, AWS SDK, AWS CLI và dĩ nhiên không thể thao tác trên giao diện AWS Web Console nha. Nhưng để dễ tiếp cận nhất, mình sẽ hướng dẫn mọi người dùng AWS CLI.
1. Cài đặt và cấu hình CLI kết nối đến tài nguyên AWS, anh em có thể tham khảo lại bài viết trước của mình. Tuy nhiên, để giới hạn quyền vừa đủ trong phạm vi S3, anh em có thể xem xét tạo policy cho IAM user tương tự như sau:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
}
2. Như đã đề cập, multipart upload chỉ thực sự hiệu quả với những object có dung lượng lớn, và theo khuyến nghị thì ta chỉ sử dụng kỹ thuật này cho các file từ 100 MB trở lên. Do đó để kiểm chứng hoạt động của nó, trong bài lab này mình sẽ tải về một sample video (~ 126 MB):
Task 3: Chia file gốc thành nhiều part
1. Bạn có thể sử dụng lệnh split (có sẵn trong các bản phân hối Linux) để tạo ra các parts (chunks)
split -b <part-size> <original-file-path>- -b <part-size>: dung lượng mong muốn của một part bạn muốn tạo
- original-file-path: đường dẫn file gốc
Ví dụ trong bài lab này mình sẽ cắt file sample_3840x2160.mp4 thành các part có dung lượng 30 MB
split -b 30MB sample_3840x2160.mp4
2. Xem danh sách các chunk files bằng lệnh: ls -lh
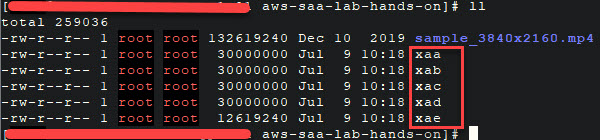
Lưu ý: Rõ ràng ở đây ta thấy lệnh split đã tạo ra 5 chunk từ xaa -> xae, mỗi chunk đều có dung lượng 30 MB, ngoài trừ file cuối xae (anh em hiểu vì sao rồi chứ 😎 ).
Task 4: Tạo một multipart upload
1. Bắt đầu khởi tạo multipart upload bằng AWS CLI theo cú pháp sau:
aws s3api create-multipart-upload --bucket [Bucket name] --key [original file name]- [Bucket name]: là tên S3 bucket cần upload lên
- [original file name]: tên file gốc

2. Anh em copy và lưu lại UploadId để sử dụng cho các bước sau.
Task 5: Upload các file chunk lên bucket
1. Bước kế tiếp, chúng ta cần upload lần lượt tất các các file chunk bucket sử dụng Chunk File Name và Part Number tương ứng như sau:
|
Chunk File Name |
Part Number |
|
xaa |
1 |
|
xab |
2 |
|
xac |
3 |
|
xad |
4 |
Cú pháp: aws s3api upload-part --bucket [bucketname] --key [filename] --part-number [number] --body [chunk file name] --upload-id [id]
Trong đó:
- –part-number [number]: part number
- –body [chunk file name]: chunk file size
- –upload-id [id]: UploadId đã lưu lại trước đó.
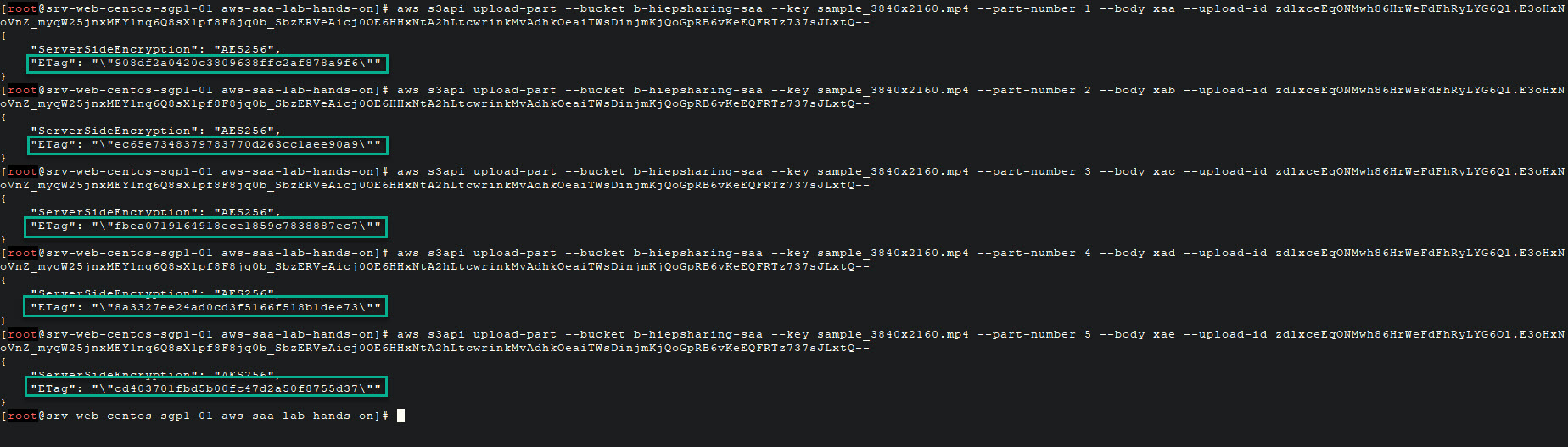
2. Sau khi upload tất cả chunk files, anh em nhớ copy và lưu lại part number và ETag tương ứng nhé.
Task 6: Tạo Multipart JSON file
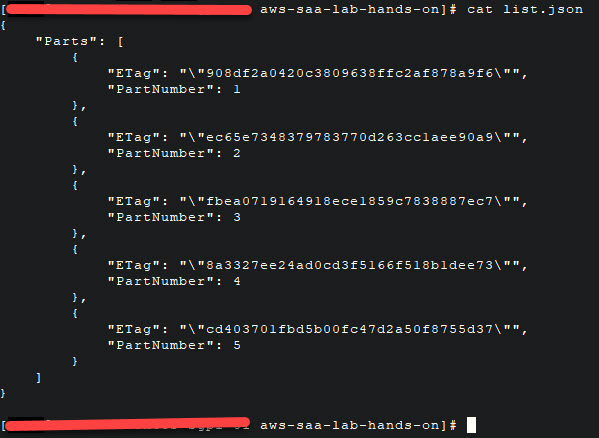
Tạo một file JSON chứa tất cả part number là ETag tương ứng đã lưu lại ở bước trước đó.
Ví dụ: đây là nội dung file list.JSON lúc mình làm lab này:
{
"Parts": [
{
"ETag": "\"908df2a0420c3809638ffc2af878a9f6\"",
"PartNumber": 1
},
{
"ETag": "\"ec65e7348379783770d263cc1aee90a9\"",
"PartNumber": 2
},
{
"ETag": "\"fbea0719164918ece1859c7838887ec7\"",
"PartNumber": 3
},
{
"ETag": "\"8a3327ee24ad0cd3f5166f518b1dee73\"",
"PartNumber": 4
},
{
"ETag": "\"cd403701fbd5b00fc47d2a50f8755d37\"",
"PartNumber": 5
}
]
}
Task 7: Hoàn thành Multi Upload lên S3 bucket
1. Phần cuối cùng là nối ghép tất cả các file chunks với thông tin trong file JSON để hoàn tất multipart upload bằng lệnh sau:
aws s3api complete-multipart-upload --multipart-upload file://[json-file-path] --bucket [bucket-name] --key [original-file-name] --upload-id [upload-id]
Nếu thành công sẽ hiển thị thông tin object như minh họa bên dưới:

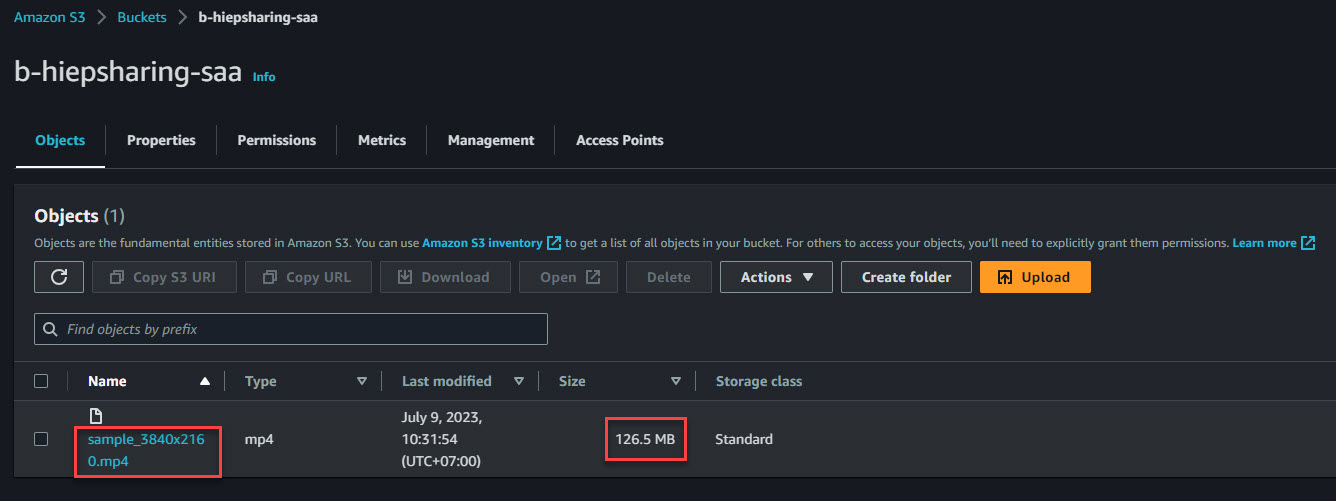
2. Quay lại giao diện AWS Web Console, truy cập vào bucket b-hiepsharing-saa sẽ thấy file gốc sample_3840x2160.mp4 với dung lượng 126 MB.
Lưu ý: Để chắc ăn, anh em có thể tải ngược file này về, mở lên xem nội dung có như file gốc tải về ở đầu lab không nhé 😆 .
Lời kết
Như vậy là mình đã hoàn thành bài lab hướng dẫn sử dụng Multipart Upload lên S3 bucket, hy vọng nó sẽ giúp được bạn trong việc quản lý dữ liệu trên S3.
Nếu có bất kỳ thắc mắc, góp ý về nội dung bài viết hoặc anh em có thêm những tip hay khác có thể chia sẻ dưới phần bình luận nhé.
Trong thời gian tới, mình sẽ cố gắng bổ sung nhiều lab khác về chủ để S3 vào serie SAA Hands-on Labs, anh em nhớ theo dõi nhé.



Để lại một phản hồi